

Panama Papers: Hoher Anspruch der Öffenlichkeit an die Auswertung
Massenleaks stellen Journalist_innen vor besondere Herausforderungen: Wie sollen sie ihre Geschichten in dem Datenwust von Millionen Dateien finden? Und welchen Anforderungen muss ihre Datenanalyse genügen, zumal die Ansprüche des Publikums an eine professionelle Informationsaufarbeitung steigen? Eine Erschließung der Daten über eine Suchfunktion, wie sie die Süddeutsche Zeitung vorgenommen hat, gehört mittlerweile zu den Basics. Die automatische Auswertung darf hier allerdings nicht stehen bleiben, mahnen Datenprofis. Denn sonst prägen unvermeidlich die Absichten und Fähigkeiten der Rechercheure die Ergebnisse zu stark.
2,6 Terabyte Daten, „das bislang größte Datenleck” sagt die Süddeutsche Zeitung. Auch sonst sind die „Panama Leaks” ein Projekt der Superlative: Sie enthalten 11,5 Mio. Dokumente aus rund 40 Jahren, die unter der Federführung von SZ und des „International Consortium for Investigative Journalists” (ICIJ) von fast 400 Journalist_innen aus mehr als 80 Ländern im Zeitraum von einem Jahr ausgewertet wurden.
Dieses Zahlenmantra findet sich immer wieder in den Berichten über die „Panama Leaks” – aber was genau sagen sie über die Qualität der Rechercheergebnisse aus? Erst einmal wenig – und die Kritik an den Veröffentlichungen rund um die Panama Papers zeigt, dass sich Journalist_innen zunehmend neuen Anforderungen an ihre Profession ausgesetzt sehen. Sie müssen gleich staatlich beauftragten Ermittlern möglichst
alles auswerten – und möglichst objektiv bewerten.
Maschinelle Aufarbeitung
Ein Blick auf die Analysemethode, die das „International Consortium for Investigative Journalists” (ICIJ) den Journalist_innen für die „Panama Papers” vorgegeben hat, ist deshalb notwendig: Die geleakten
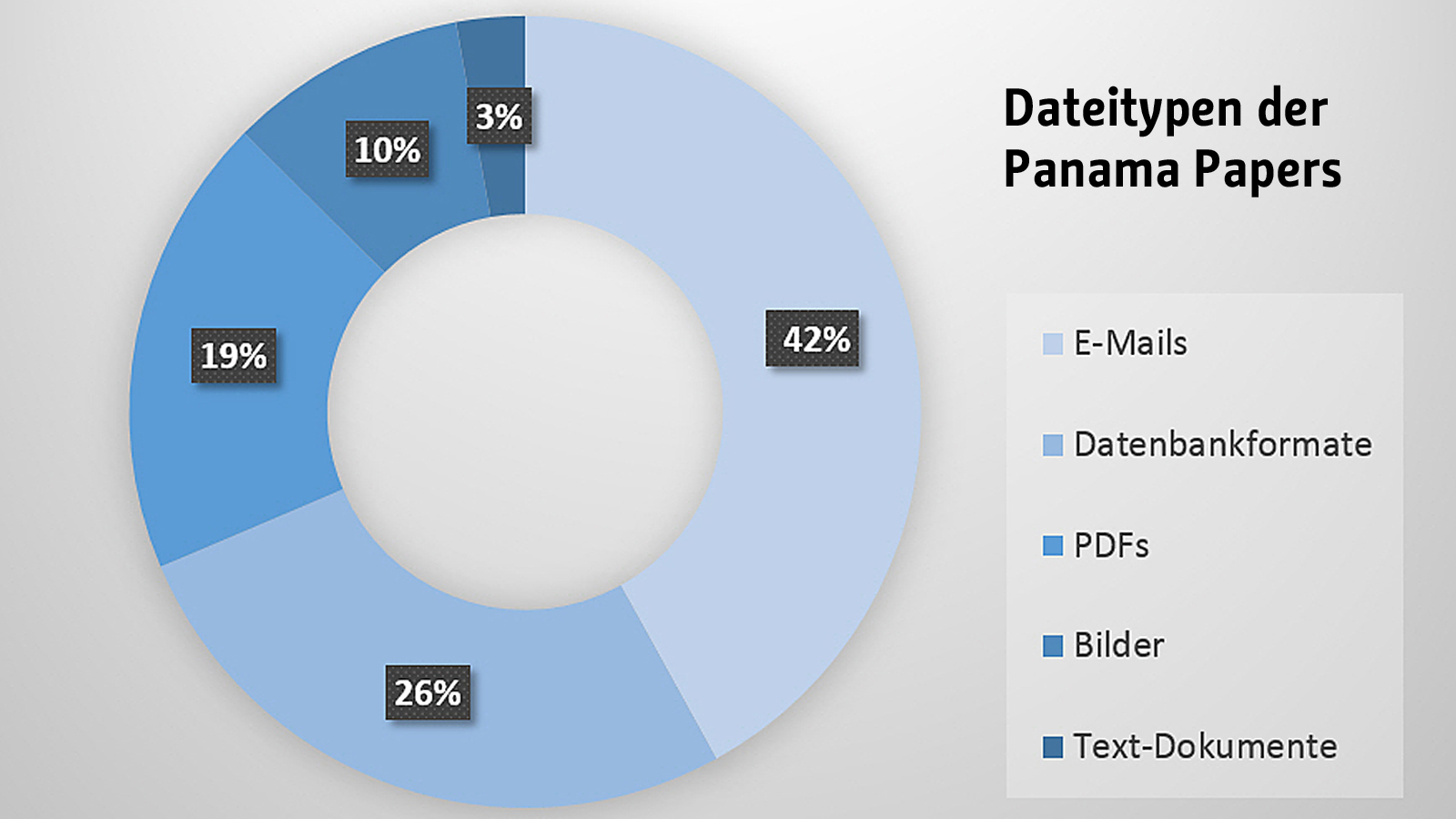
Daten lagen zunächst als E-Mails, Bilder, Datenbankformate, Word-Dokumente, Power-Point-Dateien, Excel-Dateien und eingescannte Dokumente im PDF-Format vor. Über die Auswertungsmethode berichteten die SZ-Journalist_innen, dass das ICIJ die Scans, die aus technischer Sicht zunächst Bilder darstellen, mit einem optischen Erkennungssystem (OCR) bearbeitete, um den darin enthaltenen Text in maschinenlesbaren Text umzuwandeln. In einem weiteren Schritt wurden die Dokumente in eine Datenbank überführt und indexiert.
Für diesen Prozess verwendete das ICIJ das Programm Nuix, das auch von Ermittlungsbehörden verwendet wird. Das ICIJ hatte es bereits bei den „Offshore
Leaks” im Jahr 2013 eingesetzt. Zwei Wochen dauerte es, die MossFon-Dateien elektronisch lesbar zu machen. Dabei indexierte das System den Text und erschloss die Metadaten, aus denen hervorgeht, wer die Datei wann erstellt und geändert hat. Ein Drittel der Daten konnte danach als Duplikat erkannt und wegsortiert werden. Die Journalisten griffen anschließend über eine Suchmaske auf die in einer Datenbank erfassten Dateien zu.
Die Suchergebnisse zeigten, in welchen Dateien ein Name auftauchte. Die Analyse der Daten erfolgte damit weitgehend händisch durch die Journalisten. So griffen sie beispielsweise auf Listen der Parteispenden-Affäre oder auf die UN-Sanktionsliste zurück, was eine schnell zu produzierende Skandalisierung ermöglicht. Datenanalytikerin Annette Brückner (Blogs: police-it.org und cives), die selbst große Datenauswertungen für Untersuchungsausschüsse und Sicherheitsbehörden begleitet hat, erklärt, „dass eine solche Suche immer nur die Hypothese verifizieren kann, die man vorher aufgestellt hat.” Sie hält eine derart vorgenommene Auswertung für „eine sehr subjektive Angelegenheit, da sie abhängig von den Absichten und Fähigkeiten des Fragestellers ist.”
Laut einem Screenshot von Nuix kann das Auswertungssystem bestimmte Zusammenhänge auf einer Zeitleiste anzeigen. Doch wesentliche weitere Analyseschritte bleiben seitens des Systems aus. So hätten etwa die relevanten Inhalte aus den erfassten Volltexten automatisch extrahiert werden können: Ein auf
semantische Auswerteverfahren gestützter Prozess könnte Personen- und Firmennamen, Adressangaben, Telefonnummern, Steuernummern und andere Objekte wie etwa Frachtcontainer automatisch extrahieren. Damit könnten in einem weiteren Schritt Beziehungen zwischen verschiedenen Personen über Adressen, Bankkonten, Kreditkartennummern und Mittelsmänner grafisch dargestellt werden. Dieser
Datenbestand könnte schließlich auf bestimmte Regionen, etwa Deutschland begrenzt werden, meint Brückner. Über solche systematischen Analyse-Schritte ist aber in den Berichten der SZ nichts zu lesen.
Algorithmen zur Mustererkennung
Der Anspruch der Öffentlichkeit an die Auswertung von Massenleaks ist inzwischen hoch: Nicht der journalistische Scoop wird goutiert, sondern eine möglichst hohe Objektivität. Dies legt eine an professionell-wissenschaftlichen Maßstäben orientierte Auswertung nahe. Christian Nietner, Experte für Machine Learning-Algorithmen sagt, dass „ein wesentlicher Teil der Auswertung gar nicht in der Konsolidierung der Daten besteht, sondern im Aufdecken und Validieren von unbekannten und eventuell auch nicht
offensichtlichen Mustern und Zusammenhängen in den Daten.” Mit Algorithmen zur Mustererkennung könnten automatisiert semantische, temporale, geografische oder thematische Zusammenhänge in Texten, und Bildern erkannt und sichtbar gemacht werden. Christian Nietner: „Sollten die herausragenden Möglichkeiten der Data Science dazu nicht oder nicht richtig genutzt worden sein, wäre das fahrlässig.”
Die Erstellung einer solchen Datenbank kann Monate dauern. Über diesen Arbeitsschritt hat aber die SZ nie berichtet. „Man muss ein gewisses Verständnis dafür haben, dass technisch unerfahrene Journalisten glauben, mit einem mit ihren Mitteln relativ leicht zu erstellenden Volltextsystem sei die Sache getan”, meint Annette Brückner, „zumal sie die notwendigen finanziellen und technischen Mittel zum Aufbau einer solchen Index-Datenbank wahrscheinlich von keinem Verlag finanziert bekommen.” Gleichwohl sei aber zu erwarten, dass sich die Journalist_innen die Begrenztheit ihres Ansatzes bewusstmachen und diesen offenlegen.
Ursprünglich hatte die SZ eine Veröffentlichung des gesamten Datenbank-Korpus mit dem Argument abgelehnt, dass damit unter Umständen der Whistleblower enttarnt werden könne. Anfang Mai hat das ICIJ aber einen Teil der Daten in Form einer Datenbank dennoch veröffentlicht. Erste organisierte Auswertungen fanden bereits statt, so etwa im Rahmen eines Hackathons in Brüssel. Es ist aber zu bezweifeln, dass solche Auswertungsmarathons wesentliche Erkenntnisse bringen werden, da für die Analyse wichtige Dateiinhalte wie Bankkonten, E-Mails und Finanztransaktionen vor der Veröffentlichung entfernt wurden. Auch lassen sich die Eigentümer der Schattenfirmen kaum rekonstruieren, da diese oftmals nur in den E-Mails und internen Notizen genannt werden. Gleichwohl kann mit den Daten wohl die Rolle der Banken und Anwaltskanzleien untersucht werden, die als Mittelsmänner auftreten.
Selektive Wahrnehmung
Schon sehr früh wurde die Publikationsstrategie der Süddeutschen Zeitung an den Pranger gestellt. Eine Kritik lautete: Sie vernachlässige die Amerikaner, während sie Putin in den Mittelpunkt ihrer Skandalisierung rücke. Der jedoch sei gar nicht Bestandteil des Leaks, sondern nur seine Freunde. Die Kritik ist inzwischen weitgehend verstummt. Inzwischen ist ja geklärt, dass die USA kaum Bedarf an Briefkastenfirmen haben, da einige ihrer Bundesstaaten selbst Steueroasen darstellen.
Neue Kritik wendet sich nun gegen die zurückhaltende Berichterstattung über deutsches Finanzgebaren. Nur wenige neue Akteure aus Deutschland wurden bisher ans Licht gebracht, wie eine inzwischen auf
Wikipedia eingerichtete „Liste von Personen, die in den Panama Papers genannt werden” zeigt, obgleich nach SZ-eigenen Berichten über tausend Deutsche in den Dokumenten auftauchen sollen. Dafür hatten die Protagonisten verjährter Skandale ihren Auftritt, so etwa der altgediente Helfer der deutschen Sicherheitsdienste, Werner Mauss, und die Schmiergeld-erfahrenen Siemensianer. Noch nicht wurde hingegen die Steuer- und Immobilienmarktpolitik der Bundesregierung beleuchtet. Das könnte sich lohnen, da eine Netzwerkanalyse der Parteispenden bei Zeit online schon vor Jahren eine auffallende Nähe der Immobilienbranche zur CDU aufgezeigt hat. Aufgrund der Datenbankbereinigung ist das aber mit den jetzt veröffentlichten Daten nicht von Dritten umzusetzen.
Webseiten